Wednesday, August 31, 2011
今回も、めちゃくちゃコンピューターチック話。
#興味ない人はとばしてちょ。
で、Reverse Proxy運用を開始しました。
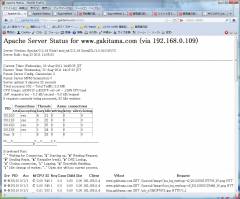
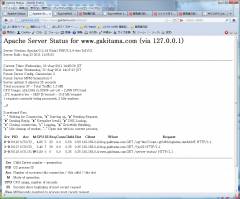
左側がフロントエンド。右側がバックエンドです。
#読めないと思うので、クリックして拡大してみてちょ。
ええっと設定状況をまとめると、
1.フロントで、静的コンテンツを返します。eventMPMを選んじゃいました。
keepalive時間は大目で、100個の接続を面倒見ます。
2.バックエンドは、動的コンテンツを返します。preforkです。
コネクションは3つ。
で、大まかな設定として、フロント側では、
って感じです。バックエンド側は普通に8080番をListenするだけ。でも、同じディレクトリを参照するようにしてます。(これのために、ちと、面倒なことしなきゃいけないんですが、kろえは後述。)
あとは、細かい話だけど、
1.フロントもバックも同じmakeだが、動的に、必要なモジュールだけ(MPMも含め)ロード。
apacheの、2.3.14あたりからの新機能です。(loadable MPM)
フロントのPMAP
なぜかスレッド分の25個が繰り返し出てきますが、表示上の話かなと、、、
右側の8772キロバイトというのが、プロセスで、Privateで使うメモリーなのですが、これが、
全部8772なので、重複して、でてるんだあ、、と勝手に思ってますが、、、(だれかおしえてちょ。)
次に、PMAPのバックエンド
おっと、プロセス固有で、40280キロバイトも使ってますね。
これは、、、実は、そのうち32Mは、APCで使ってます。(後述)
3.DirectoryIndexに、index.html index.php とかしてると、ちょっと面倒な苦労があります。
backendにindex.phpをさがしに行くとバックエンドで動いてしまうので、ちょっと工夫がいる。
4.ProxyPassReverseは設定してないけど動いてます。
5.フロント側には、メモリーが勿体無いので、mod_phpをリンクしてないんですけど、そうすると、
.htaccess に、php_valueとか書いてると、これもまた、面倒なことを考えなきゃいけない。
6.同じようなことを実現するのに、fcgi proxyというのが、有るらしいので、こちらをいろいろと調べたが、
fcgistarterの使い方がわからんちんで、もっちょっと待とうかな。
ちなみに、他にも、選択肢がいろいろあります。(mod_fcgiとか、mod_fastcgiとかあります。)
が、mod_fcgi_proxyが、主流になるという予想なんですが。(私の予想はだいたい外れますけど。)
ま、そんなところかな。
で、APCも導入しました。
これ、PHPのコンパイル結果を、キャッシュしてくれるというもの。
とりあえず、うちのサイトの思いつくPHPを動かした後の状態。
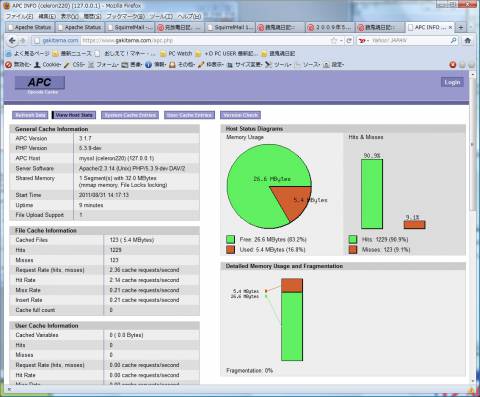
キャッシュの32Mのうち、5.4Mだけで、うちのサイトはほとんど入っちゃう、って感じですね。
この32Mは、プロセス同士で共有されてると思うんですが、PMAPでprivateのところにでてくるというのは、なんじゃろな。(これもだれか教えて。
あ、以下のように無名ブロックのところに出てきます。
で、とりあえず、効果としては、apacheのABで計ったところ、PHPのCPU使用時間は、3分の2程度には、なっています。
ま、いいっか、、、
、
続きを見る
#興味ない人はとばしてちょ。
で、Reverse Proxy運用を開始しました。
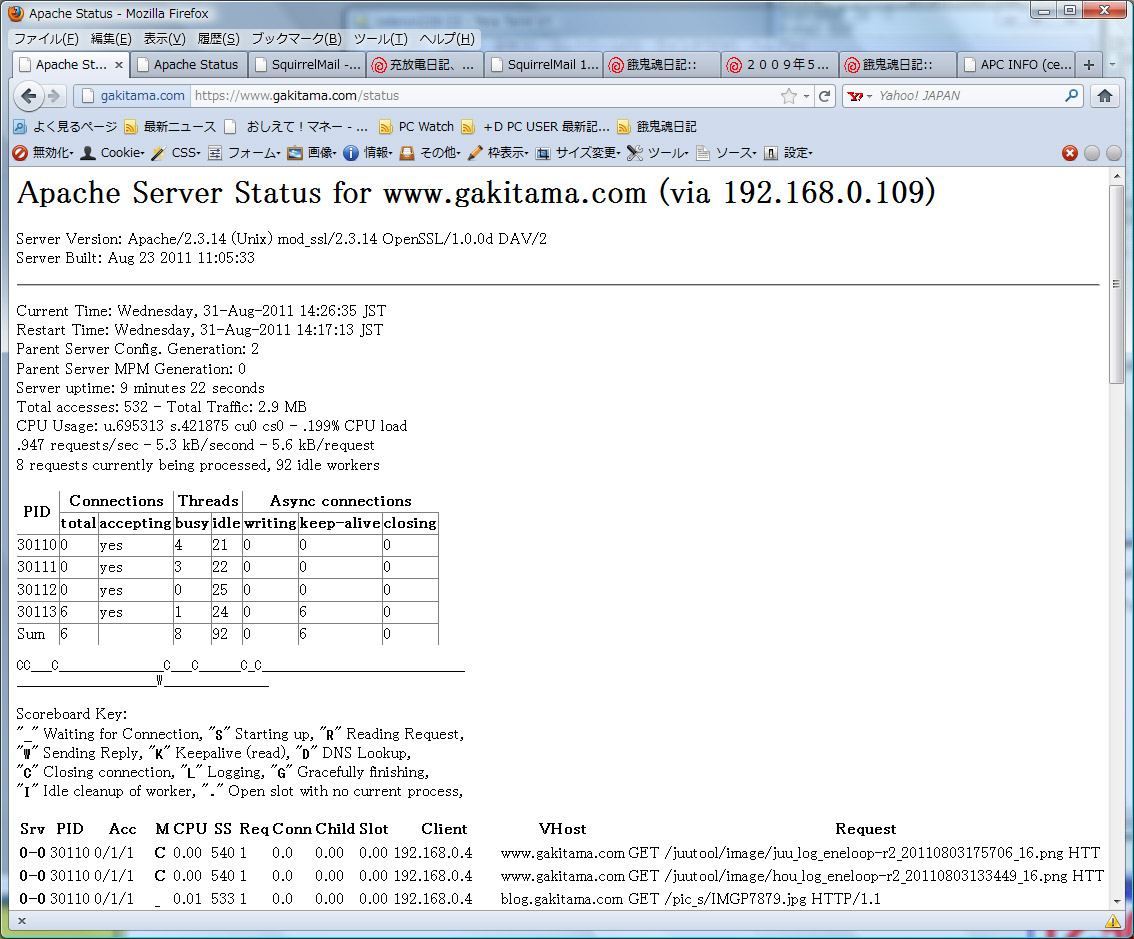
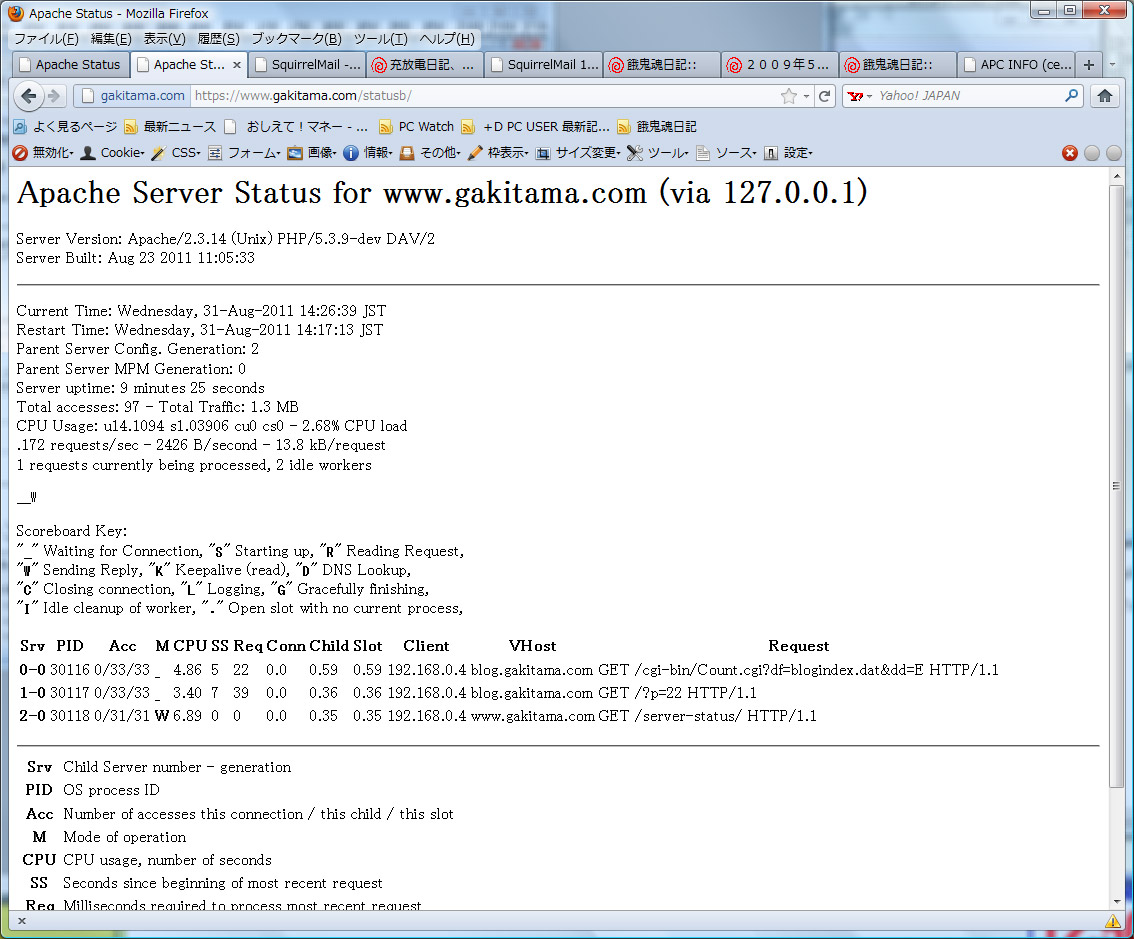
左側がフロントエンド。右側がバックエンドです。
#読めないと思うので、クリックして拡大してみてちょ。
ええっと設定状況をまとめると、
1.フロントで、静的コンテンツを返します。eventMPMを選んじゃいました。
keepalive時間は大目で、100個の接続を面倒見ます。
2.バックエンドは、動的コンテンツを返します。preforkです。
コネクションは3つ。
で、大まかな設定として、フロント側では、
RewriteCond %{LA-U:REQUEST_FILENAME} \.(cgi|pl|php)$
RewriteRule ^/(.*) http://www.gakitama.com:8080/$1 [L,P,QSA]
って感じです。バックエンド側は普通に8080番をListenするだけ。でも、同じディレクトリを参照するようにしてます。(これのために、ちと、面倒なことしなきゃいけないんですが、kろえは後述。)
あとは、細かい話だけど、
1.フロントもバックも同じmakeだが、動的に、必要なモジュールだけ(MPMも含め)ロード。
apacheの、2.3.14あたりからの新機能です。(loadable MPM)
フロントのPMAP
# pmap 30110 | grep Total
Total Kb 14504 8064 7060 8772
中略、、、25回繰り返し。スレッド分出てるのかな?
Total Kb 14504 8064 7060 8772
#
なぜかスレッド分の25個が繰り返し出てきますが、表示上の話かなと、、、
右側の8772キロバイトというのが、プロセスで、Privateで使うメモリーなのですが、これが、
全部8772なので、重複して、でてるんだあ、、と勝手に思ってますが、、、(だれかおしえてちょ。)
次に、PMAPのバックエンド
# pmap 30116 | grep Total
Total Kb 58696 22680 19048 40280
おっと、プロセス固有で、40280キロバイトも使ってますね。
これは、、、実は、そのうち32Mは、APCで使ってます。(後述)
3.DirectoryIndexに、index.html index.php とかしてると、ちょっと面倒な苦労があります。
backendにindex.phpをさがしに行くとバックエンドで動いてしまうので、ちょっと工夫がいる。
4.ProxyPassReverseは設定してないけど動いてます。
5.フロント側には、メモリーが勿体無いので、mod_phpをリンクしてないんですけど、そうすると、
.htaccess に、php_valueとか書いてると、これもまた、面倒なことを考えなきゃいけない。
6.同じようなことを実現するのに、fcgi proxyというのが、有るらしいので、こちらをいろいろと調べたが、
fcgistarterの使い方がわからんちんで、もっちょっと待とうかな。
ちなみに、他にも、選択肢がいろいろあります。(mod_fcgiとか、mod_fastcgiとかあります。)
が、mod_fcgi_proxyが、主流になるという予想なんですが。(私の予想はだいたい外れますけど。)
ま、そんなところかな。
で、APCも導入しました。
これ、PHPのコンパイル結果を、キャッシュしてくれるというもの。
とりあえず、うちのサイトの思いつくPHPを動かした後の状態。
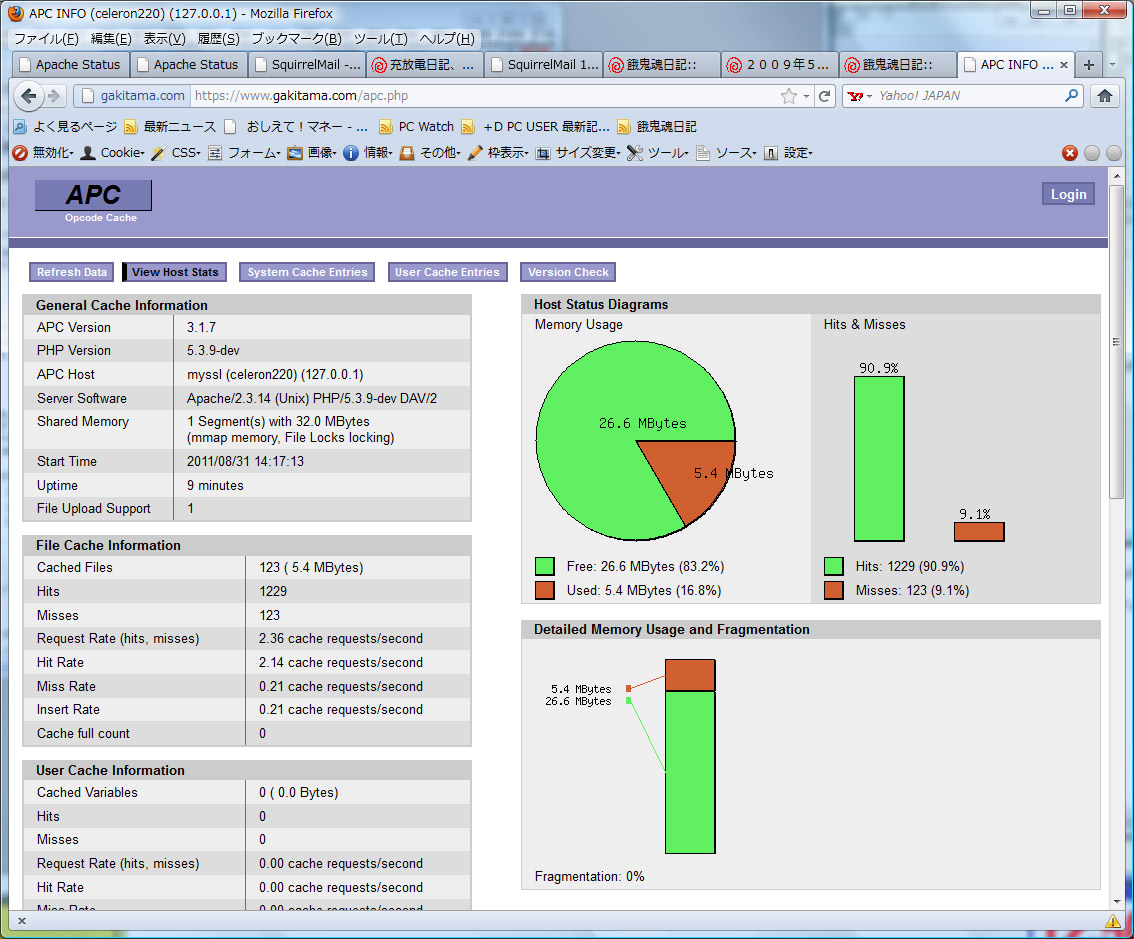
キャッシュの32Mのうち、5.4Mだけで、うちのサイトはほとんど入っちゃう、って感じですね。
この32Mは、プロセス同士で共有されてると思うんですが、PMAPでprivateのところにでてくるというのは、なんじゃろな。(これもだれか教えて。
あ、以下のように無名ブロックのところに出てきます。
# pmap 30116 | tail
29620000 16 4 - 16 rwx [ anon ]
29700000 1024 980 - 1024 rwx [ anon ]
29800000 32768 5552 - 32768 rwx [ anon ]
2B800000 1024 808 - 1024 rwx [ anon ]
2BF00000 1024 1020 - 1024 rwx [ anon ]
BFBE0000 128 48 - 128 rwx [ anon ]
-------- ------- ------- ------- -------
Total Kb 58696 23424 19048 40280
#
で、とりあえず、効果としては、apacheのABで計ったところ、PHPのCPU使用時間は、3分の2程度には、なっています。
ま、いいっか、、、
、





